
In the realm of Large Language Models (LLMs), benchmarking emerges as a critical tool for fine-tuning their potential and ensuring their applicability across various domains. Given the complexity and diversity of LLMs, understanding and applying the right benchmarking techniques becomes essential to harness their capabilities effectively. This article focuses on exploring the multifaceted aspects of benchmarking LLMs — why it's crucial, how it's conducted, and its impact on model selection and optimization.
Benchmarking, in this context, goes beyond mere performance evaluation. It's a strategic process that guides the development of LLMs, ensuring they are not only accurate and efficient but also relevant to specific use cases. We'll delve into its importance in the lifecycle of LLMs, exploring both public and private testing methods, and introduce our internal test, BACON (Benchmarking Attention & Confabulatory Output in Neural networks), as a case study. This will set the stage for a deeper discussion on various assessment techniques, including metric evaluation, advanced model judgments, and human reviews, providing insights into crafting LLMs that are not just powerful but also precisely tuned for their intended applications.
Benchmarking is pivotal in pinpointing the most appropriate Large Language Model (LLM) for specific use cases. This process involves comparing various models based on criteria such as accuracy, efficiency, and contextual understanding. For instance, a model like GPT-3 might be ideal for creative content generation due to its expansive training dataset and nuanced language understanding. Conversely, a model like Deepseek Coder , with its array of code language models trained on a massive 2T token dataset comprising 87% code and 13% natural language in both English and Chinese, stands out for applications that demand high-level coding proficiency.
In customer service scenarios, an LLM that excels in understanding and generating conversational language would be preferable, while for technical domains like programming or scientific research, models trained on specialized datasets would offer more accurate and relevant outputs. Benchmarking allows organizations to make informed decisions by evaluating these models against their specific needs, ensuring the chosen LLM delivers the desired performance and results.
As LLMs evolve, new versions are regularly released, each claiming improved capabilities. Benchmarking is essential in rapidly assessing these versions, enabling developers and users to stay abreast of the most advanced and effective models. Through benchmarking, changes in performance, understanding of context, and response accuracy can be quantified, providing clear insights into whether an upgrade is beneficial.
In the development cycle, benchmarking acts as a feedback loop. It informs developers of the strengths and weaknesses of each model iteration, guiding subsequent enhancements. This ongoing process of benchmarking and development ensures that LLMs continue to evolve in a direction that meets user demands and adapts to the changing technological landscape.

Public benchmark tests are vital in establishing a standardized baseline for evaluating LLMs. They provide a universal platform where models from different developers can be compared on equal footing. Public benchmarks, like ARC and TruthfulQA, are crucial for assessing the general capabilities of LLMs, ensuring they meet a certain standard of performance.
However, public benchmarks also have limitations. They may not cover specific use cases or niche applications, and there's a risk of models being overfit to perform well on these tests, possibly at the expense of real-world applicability. Moreover, as these benchmarks become widely used, they can lose their effectiveness in differentiating between advanced models, which might perform similarly on these standardized tests.
Private testing addresses the limitations of public benchmarks by allowing for more tailored and specific evaluations. These tests are particularly crucial in fields with unique requirements, such as medical, legal, or financial services. Private benchmarks can be designed to simulate real-world scenarios specific to these industries, providing a more accurate assessment of how a model would perform in practical applications.
Private testing also plays a key role in preventing model bias and overfitting. By using proprietary or specialized datasets, it ensures that the LLM isn't just tuned to excel in publicly available tests but is genuinely capable of handling unique, real-world data. This is especially important in avoiding the pitfall of models appearing proficient due to their familiarity with public test datasets, a phenomenon known as "teaching to the test."
Balancing public and private benchmarking is crucial for a comprehensive evaluation of LLMs. While public benchmarks provide a common ground for initial assessment, private tests offer depth and specificity, ensuring that the chosen LLM is not only generally competent but also finely tuned to specific operational environments. This holistic approach to benchmarking ensures the deployment of LLMs that are both versatile and specialized, capable of performing reliably across a broad spectrum of tasks and in particular niche applications.

The Benchmarking Attention & Confabulatory Output in Neural networks (BACON) test
transcends traditional performance metrics, focusing on the nuanced evaluation of
neural networks. It assesses their ability to interpret context-driven questions,
sustain attention during extended tasks, and reduce erroneous or hallucinatory
responses.
This test emerged as a response to a challenge faced in DocsGPT, a scenario where
queries are linked with substantial contextual data.
BACON adopts a holistic approach in its methodology. The test encompasses a variety of question types, sourced from extensive scientific texts, complex coding queries, and detailed instructional prompts. This approach ensures that the model's capabilities are evaluated across a broad spectrum of scenarios, mirroring real-world applications more effectively. In BACON, the assessment criteria focuses on how a model integrates context understanding, resists generating inaccurate information, and maintains attention.
In practical scenarios, particularly in contexts where precision and contextual
relevance are crucial, BACON has been an invaluable tool. In environments like
DocsGPT, which are heavily reliant on context, BACON aids in identifying models
that effectively interpret and respond to extensive interactions.
Internally, we employ a combination of the LLM judge and human judgment approaches
to evaluate models using BACON. While we currently keep the specifics of this test
internal to prevent data poisoning, we are open to collaborations. For organizations
interested in evaluating their models with BACON, we invite you to reach out.
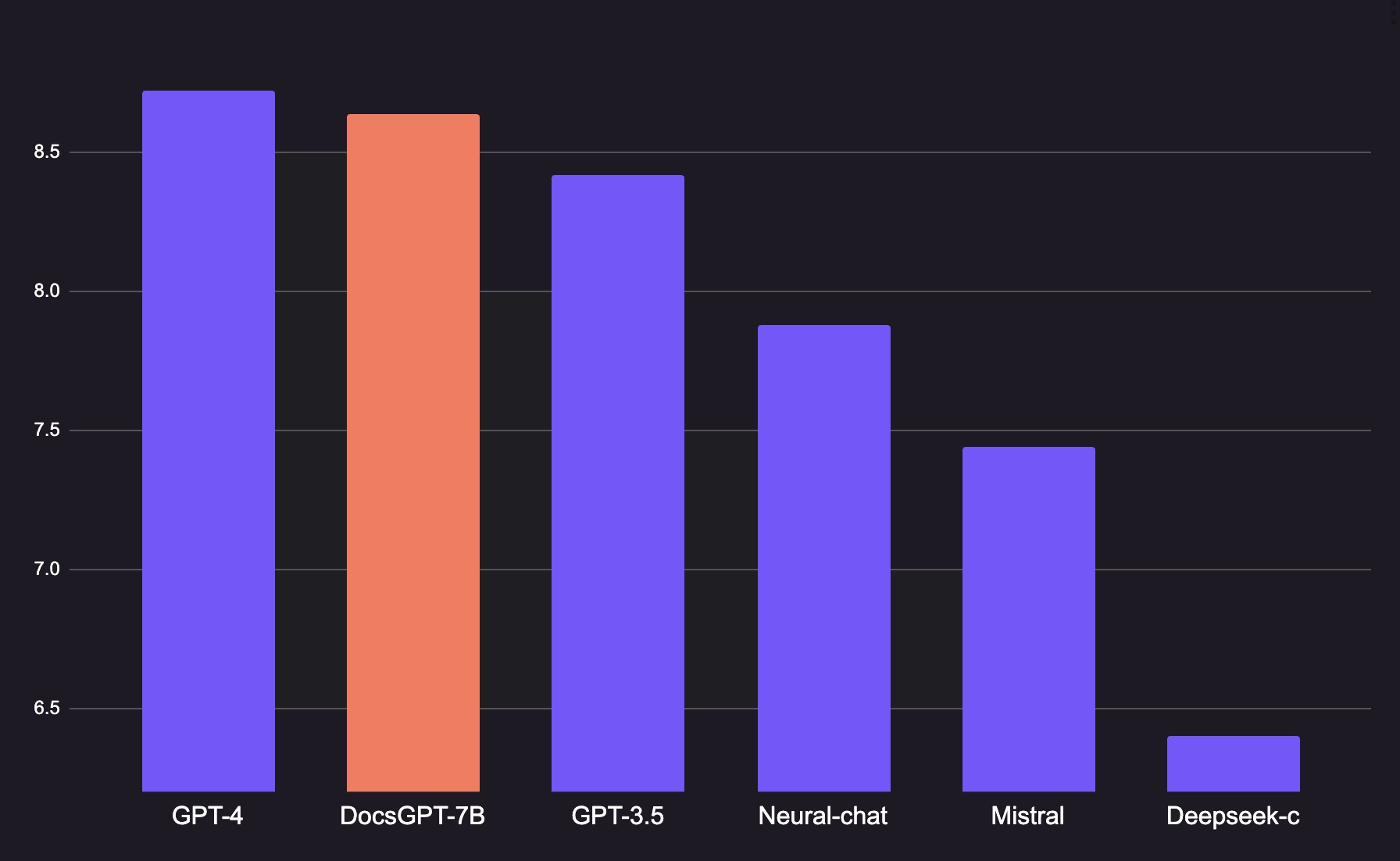
Metric-based assessment is a cornerstone in evaluating the performance of Large Language Models (LLMs). Quantitative measures like Rouge and BLEU scores are widely used for this purpose. These metrics primarily focus on comparing the model-generated text against a set of reference texts, evaluating aspects like coherence, grammaticality, and relevance.
In this context, the lm-evaluation-harness library emerges as a significant tool. This open-source platform facilitates the application of various benchmarks on LLMs.
The advantage of metric-based assessment lies in its objectivity and ability to provide quick standardized benchmarks across different models. However, the limitations are equally noteworthy. These metrics often fail to capture the nuances of language, such as the context or semantic depth, potentially leading to an overemphasis on syntactical accuracy over meaningful content.
The LMSYS Org approach represents an innovative leap in LLM benchmarking. It involves using advanced models like GPT-4 to assess the outputs of other LLMs. This method allows for a more nuanced understanding of a model's capabilities, particularly in terms of contextual understanding and response generation.
While the use of advanced models as judges offers a deeper insight into the qualitative aspects of LLM outputs, it also brings challenges. The primary concern is the inherent bias — since these advanced models are themselves subject to limitations and biases, their judgments might not always reflect an objective assessment.
Human judgment plays an indispensable role in the benchmarking process of LLMs. Human evaluators can understand context, infer subtleties, and appreciate creativity in a way automated systems currently cannot. They are essential in assessing the qualitative aspects of model outputs, such as cultural relevance, empathy in responses, and overall user experience.
However, balancing human insights with automated assessments is crucial. Human evaluation, while insightful, can be subjective and influenced by individual biases. Therefore, a combination of human judgment and automated metric-based assessments often provides the most comprehensive evaluation.

Throughout this article, we have explored the multifaceted nature of benchmarking LLMs. From the significance of metric-based assessments and their limitations to the innovative use of advanced models as evaluators and the irreplaceable role of human judgment, it's clear that a comprehensive approach is vital for accurately assessing these complex systems.
The landscape of LLM benchmarking is continuously evolving, paralleling the advancements in AI technology. As these models become more integrated into various sectors, the importance of robust, multi-dimensional benchmarking grows. This evolution not only ensures the effectiveness and reliability of LLMs but also drives their ethical and responsible development and implementation, shaping a future where AI complements and enhances human capabilities.
Whether you are seeking guidance in conducting comprehensive assessments, training custom LLMs tailored to your specific needs, or just setting up DocsGPT our team stands ready to assist. Don't hesitate to reach out for specialized assistance and insights that can help you harness the full potential of AI tools.
Get in touch